 2010年7月9日
2010年7月9日
Java的内存模型中Thread会附有自己的堆栈,寄存器,必要时需要和主存即heap之间同步。
可以使用Synchornized关键字和Concurrent包中的Lock可以保证线程互斥和可见性。
互斥性体现在类锁或者对象锁上,每个对象自身都包含一个监视器,该监视器是一个每次只能被一个线程所获取进入的临界区,可以通过wait和notify来退出和准入临界区。可以看出这是一个生产者-消费者的模型。而Concurrent包中的Lock为了能够获得更好的性能和更好的扩展性,以及不依赖于关键字的可读代码,自己实现了这样一个生产消费队列,也就是AbstractQueuedSynchronizer,被称为AQS的机制。每个Lock都内置了一个AbstractQueuedSynchronizer。需要说明的是AbstractQueuedSynchronizer内部实现采用了CAS机制,通过getState, setState, compareAndSetState访问控制一个32bit int的形式进行互斥。
那么可见性是如何保证的呢?
对于关键字的同步机制,其实可见性就是线程和主存之间的同步时机问题。共有4个时间点需要注意:
1 获取或释放类锁/对象锁的时候。Thread保证reload/flush全部变更
2 volatile就是flush on write或者reload on read
3 当线程首次访问共享变量时,可以得到最新的结果。
题外:所以在构造方法中公布this时很危险的。简单的说,就是构造时不逃脱任何变量,不开启新的线程,只做封装。关于安全构造,请参考
http://www.ibm.com/developerworks/cn/java/j-jtp0618/#resources
4 线程结束时,所有变更会写回主存
关于Concurrent Lock如何实现可见性的问题,Doug Lea大侠,只在他的论文中提到,按照JSR133,Unsafe在getState, setState, compareAndSetState时保证了线程的变量的可见性,不需要额外的volatile支持,至于具体这些native做了哪些magic就不得而知了,总之,最后的contract就是保证lock区间的共享变量可见性。开发团队被逼急了就这样回答:
There seems to be a real reluctance to explain the dirty details. I think the question was definitely understood on the concurrent interest thread, and the answer is that synchronized and concurrent locking are intended to be interchangable in terms of memory semantics when implemented correctly. The answer to matfud's question seems to be "trust us.”
不过这个地方的确是开发团队给我们用户迷惑的地方,在同样应用了CAS机制的Atomic类中,都内嵌了volatile变量,但是再lock块中,他告诉我们可以保证可见性。
感兴趣的同学可以下面的两个thread和Doug Lea的thesis:
http://altair.cs.oswego.edu/pipermail/concurrency-interest/2005-June/001587.html
http://forums.sun.com/thread.jspa?threadID=631014&start=15&tstart=0
http://gee.cs.oswego.edu/dl/papers/aqs.pdf
2010年7月7日
2010年7月2日
ThreadLocal是一种confinement,confinement和local及immutable都是线程安全的(如果JVM可信的话)。因为对每个线程和value之间存在hash表,而线程数量未知,从表象来看ThreadLocal会存在内存泄露,读了代码,发现实际上也可能会内存泄露。
事实上每个Thread实例都具备一个ThreadLocal的map,以ThreadLocal Instance为key,以绑定的Object为Value。而这个map不是普通的map,它是在ThreadLocal中定义的,它和普通map的最大区别就是它的Entry是针对ThreadLocal弱引用的,即当外部ThreadLocal引用为空时,map就可以把ThreadLocal交给GC回收,从而得到一个null的key。
这个threadlocal内部的map在Thread实例内部维护了ThreadLocal Instance和bind value之间的关系,这个map有threshold,当超过threshold时,map会首先检查内部的ThreadLocal(前文说过,map是弱引用可以释放)是否为null,如果存在null,那么释放引用给gc,这样保留了位置给新的线程。如果不存在slate threadlocal,那么double threshold。除此之外,还有两个机会释放掉已经废弃的threadlocal占用的内存,一是当hash算法得到的table index刚好是一个null key的threadlocal时,直接用新的threadlocal替换掉已经废弃的。另外每次在map中新建一个entry时(即没有和用过的或未清理的entry命中时),会调用cleanSomeSlots来遍历清理空间。此外,当Thread本身销毁时,这个map也一定被销毁了(map在Thread之内),这样内部所有绑定到该线程的ThreadLocal的Object Value因为没有引用继续保持,所以被销毁。
从上可以看出Java已经充分考虑了时间和空间的权衡,但是因为置为null的threadlocal对应的Object Value无法及时回收。map只有到达threshold时或添加entry时才做检查,不似gc是定时检查,不过我们可以手工轮询检查,显式调用map的remove方法,及时的清理废弃的threadlocal内存。需要说明的是,只要不往不用的threadlocal中放入大量数据,问题不大,毕竟还有回收的机制。
综上,废弃threadlocal占用的内存会在3中情况下清理:
1 thread结束,那么与之相关的threadlocal value会被清理
2 GC后,thread.threadlocals(map) threshold超过最大值时,会清理
3 GC后,thread.threadlocals(map) 添加新的Entry时,hash算法没有命中既有Entry时,会清理
那么何时会“内存泄露”?当Thread长时间不结束,存在大量废弃的ThreadLocal,而又不再添加新的ThreadLocal(或新添加的ThreadLocal恰好和一个废弃ThreadLocal在map中命中)时。
2010年6月29日
文档应该包括两大部分,一部分是清晰的代码结构和注释,比如Concurrent API就是这样,还有一部分是文字文档,包括三个小部分:一是开发文档,应该讲架构和功能;二是索引文档,详细介绍功能和参数,三是用户文档,包括安装和使用说明
文档最困难的莫过于版本的一致性,当软件升级后,一些obsolete的内容和新的feature很难同步。要是架构发生了变化,那就更困难了。一般document team都不是太精于技术,所以也会产生一些问题。
只能说任何事物永远都有改进的空间,但是同样也永远没有达到完美的程度
2010年6月25日
摘要: 1 根据cpu core数量确定selector数量
2 用一个selector服务accept,其他selector按照core-1分配线程数运行
3 accept selector作为生产者把获得的请求放入队列
4 某个selector作为消费者从blocking queue中取出请求socket channel,并向自己注册
5 当获得read信号时,selector建立工作...
阅读全文
多线程的优点:
1 多核利用
2 为单个任务建模方便
3 异步处理不同事件,不必盲等
4 现代的UI也需要它
风险:
1 同步变量易错误
2 因资源限制导致线程活跃性问题
3 因2导致的性能问题
用途:
框架,UI,Backend
线程安全的本质是什么:
并非是线程和锁,这些只是基础结构,本质是如何控制共享变量访问的状态
什么是线程安全:
就是线程之间的执行
还没有发生错误,就是没有发生意外
一个线程安全的类本身封装了对类内部方法和变量的异步请求,调用方无需考虑线程安全问题
无状态的变量总是线程安全的
原子性:
完整执行的单元,如不加锁控制,则会发生竞态条件,如不加锁的懒汉单例模式,或者复合操作。
锁,内在锁,重入:
利用synchronized关键字控制访问单元,同一线程可以重入锁内部,避免了面向对象产生的问题。同一变量的所有出现场合应该使用同一个锁来控制。synchronized(lock)。
即使所有方法都用synchronized控制也不能保证线程安全,它可能在调用时编程复合操作。
活跃性和性能问题:
过大的粒度会导致这个问题,用锁进行异步控制,导致了线程的顺序执行。
简单和性能是一对矛盾,需要适当的取舍。不能在没有考虑成熟的情况下,为了性能去牺牲简洁性。
要尽量避免耗时操作,IO和网络操作中使用锁
Store包含两个数据缓存 - snapshot和data,grid,combo等控件的显示全部基于data,而snapshot是数据的完整缓存,当首次应用过滤器时,snapshot从data中备份数据,当应用过滤器时,filter从snapshot获取一份完整的数据,并在其中进行过滤,过滤后的结果形成了data并传递给展示,及data总是过滤后的数据,而snapshot总是完整的数据,不过看名字让人误以为它们的作用正好相反。
相应地,当进行store的增删改时,要同时维护两个缓存。
问题
Store包含两个增加Record的方法,即insert和add,其中的insert没有更新snapshot所以当重新应用filter时,即data被重新定义时,在data中使用insert新增的记录是无效的。
解决方法
用add不要用insert,如果用insert,记得把数据写进snapshot: store.snapshot.addAll(records)
摘要: 在Extjs中构造N级联动下拉的麻烦不少,需定制下拉数据并设定响应事件。通过对Combo集合的封装,无需自己配置Combo,只需设定数据和关联层级,即可自动构造出一组支持正向和逆向过滤的联动下拉并获取其中某一个的实例。
如:
数据:
Ext.test = {};
Ext.test.lcbdata&nb...
阅读全文
目前主流的SSH开发架构中,为减轻开发者工作,便于管理开发过程,往往用到一些公共代码和组件,或者采用了基于模版的代码生成机制,对于后台的DAO,Service等因为架构决定,代码生成必不可少,但是在前端页面的实现上,却可以有两种不同的思路,一种是把配置信息直接封装成更高级别的组建,一种是进行代码生成。请大家讨论一下这两种方案的优劣,这里先抛砖引玉了。
相同点:
配置信息:XML OR 数据库
控件化:
优点:
1 易于添加公共功能
2 修改配置数据直接生效
3 代码结构清晰,对开发者友好
缺点:
1 重组内存中对象结构,性能没有代码生成好(但渲染时间相同)
2 仅能控制组件自身封装的配置,不支持个性化修改,如果配置文件不支持的参数,则控件不支持
3 必须保证每个控件一个配置
代码生成:
优点:
1 性能较好
2 易于定制内容
3 可以只配置一个模版,然后做出多个简单的修改
缺点:
1 不能针对多个页面同时添加公共功能
2 业务修改需要重新生成代码
3 开发者需要修改自动生成的代码,并需要了解一些底层的实现结构
=====================20091029
代码生成并不能提高工作效率,尤其是针对复杂的富客户端开发
开发组件可提提供一种有效的选项,但是在运行效率和内存处理上需要细心处理
2009年3月6日
最近在学习jBPM和Javascript,所以按照一些相关概念自己写了下面的200行代码的“工作流引擎”,工作流管理系统包含了流程定义,引擎,及应用系统三个主要部分,下面的代码实现了流程的分支合并,目前只支持一种环节上的迁移。拷贝到html,双击就可以跑起来。
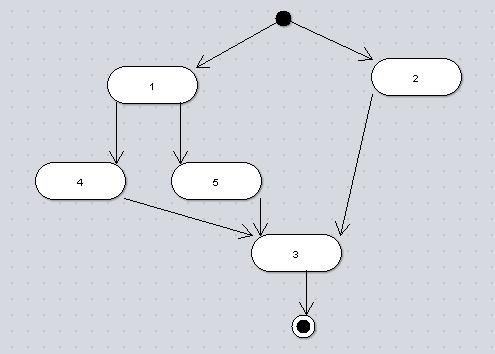
var workflowDef = {
start:{
fn:"begin", //对应处理方法可以在内部定义,也可以在外部定义
next:["task1","task2"]
},
end:"end",
tasks:[{
id:"task1",
fn:function(){
alert("执行任务一");
},
before:function(){
alert("执行任务一前");
},
after:function(){
alert("执行任务一后");
},
next:["task4","task5"]
},{
id:"task2",
fn:function(){
alert("执行任务二");
},
before:function(){
alert("执行任务二前");
},
after:function(){
alert("执行任务二后");
},
next:["task3"]
},{
id:"task3",
fn:function(){
alert("执行任务三");
},
before:function(){
alert("执行任务三前");
},
after:function(){
alert("执行任务三后");
},
//定义合并的数量
merge: 3,
next:"EOWF"
},{
id:"task4",
fn:function(){
alert("执行任务四");
},
before:function(){
alert("执行任务四前");
},
after:function(){
alert("执行任务四后");
},
next:["task3"]
},{
id:"task5",
fn:function(){
alert("执行任务五");
},
before:function(){
alert("执行任务五前");
},
after:function(){
alert("执行任务五后");
},
next:["task3"]
}]
}
//////////定义引擎////////////
Yi = {};
Yi.Utils = {};
Yi.Utils.execute = function(o){
if(typeof o != 'function')
eval(o)();
else
o();
}
//工作流类
Yi.Workflow = function(workflowDef){
this.def = workflowDef;
this.tasks = this.def.tasks;
}
//public按照环节id查找查找
Yi.Workflow.prototype.findTask = function(taskId){
for(var i=0;i<this.tasks.length;i++){
if(this.tasks[i].id == taskId)
return this.tasks[i];
}
}
//public启动工作流
Yi.Workflow.prototype.start = function(){
this.currentTasks = [];
Yi.Utils.execute(this.def.start.fn);
for(var i=0;i<this.def.start.next.length;i++){
this.currentTasks[i] = this.findTask(this.def.start.next[i]);
Yi.Utils.execute(this.currentTasks[i].before);
}
}
//private
Yi.Workflow.prototype.findCurrentTaskById = function(taskId){
for(var i=0;i<this.currentTasks.length;i++){
if(this.currentTasks[i].id == taskId)
return this.currentTasks[i];
}
return null;
}
//private
Yi.Workflow.prototype.removeFromCurrentTasks = function(task){
var temp = [];
for(var i=0;i<this.currentTasks.length;i++){
if(!(this.currentTasks[i] == task))
temp.push(this.currentTasks[i]);
}
this.currentTasks = temp;
temp = null;
}
//public触发当前环节
Yi.Workflow.prototype.signal = function(taskId){
//只处理当前活动环节
var task = this.findCurrentTaskById(taskId);
if(task == null){
alert("工作流未流转到此环节!");
return;
}
//对于合并的处理
if(task.merge != undefined){
if(task.merge != 0){
alert("工作流流转条件不充分!");
return;
}else{
Yi.Utils.execute(task.before);
}
}
//触发当前环节
Yi.Utils.execute(task.fn);
//触发后动作
Yi.Utils.execute(task.after);
//下一步如果工作流结束
if(task.next === "EOWF"){
Yi.Utils.execute(this.def.end);
delete this.currentTasks;
return;
}
//遍历下一步环节
this.removeFromCurrentTasks(task);
for(var i=0;i<task.next.length;i++){
var tempTask = this.findTask(task.next[i]);
if(!tempTask.inCurrentTasks)
this.currentTasks.push(tempTask);
if(tempTask.merge != undefined){
tempTask.merge--;
tempTask.inCurrentTasks = true;
}
else
Yi.Utils.execute(tempTask.before);
}
}
//public获取当前的活动环节
Yi.Workflow.prototype.getCurrentTasks = function(){
return this.currentTasks;
}
//public获取流程定义
Yi.Workflow.prototype.getDef = function(){
return this.def;
}
////////应用系统///////////////
var wf = new Yi.Workflow(workflowDef);
alert("启动工作流");
wf.start();
alert("尝试手工执行任务3,返回工作流没有流转到这里");
wf.signal("task3");
alert("分支开始");
alert("手工执行任务1");
wf.signal("task1");
alert("手工执行任务2");
wf.signal("task2");
alert("手工执行任务4");
wf.signal("task4");
alert("手工执行任务5");
wf.signal("task5");
alert("手工执行任务3");
wf.signal("task3");
function begin(){
alert("流程开始,该函数在外部定义");
}
function end(){
alert("流程结束");
}